
Imagine your agency lands a major enterprise client—a retailer with over a million product pages. You launch their SEO campaign with brilliant content and high-quality links, but weeks later, a huge portion of their key pages still aren’t indexed.
A quick check in Google Search Console reveals the problem: Googlebot is spending most of its time on obscure URLs with weird tracking parameters, completely ignoring the new product lines.
If this scenario feels uncomfortably familiar, you’re not alone. According to data from Botify, on large retail sites, an average of 58% of pages are never crawled by Google.
That’s more than half the site, invisible to the world’s largest search engine. For an agency, this isn’t just a technical issue; it’s a hidden barrier to delivering client results. The culprit is almost always wasted crawl budget, and manually fixing it on a massive site is like trying to empty an ocean with a bucket.
The solution lies in automation. This guide lays out a scalable workflow for agencies to diagnose and optimize crawl budget, turning a resource-draining problem into a powerful source of organic growth for your largest clients.
What is Crawl Budget and Why Does It Matter for Large Sites?
Think of crawl budget as a discovery allowance Google gives your website. Every day, Googlebot has a certain amount of resources and time it can spend exploring your pages.
For a small, five-page brochure site, that allowance is more than enough. But for a sprawling enterprise site with hundreds of thousands or millions of URLs, that budget becomes precious.
Google itself puts it plainly: “Wasting server resources on low-value pages will drain crawl budget from the pages that do actually have value, which may cause a significant delay in discovering great content on a site.”
Every second Googlebot spends on a broken link, a redirect chain, or a duplicate page generated by a URL parameter is a second it does not spend on a critical product page or a newly published blog post.
This isn’t just a theoretical problem. A study by Onely found a direct correlation between improved crawl budget utilization and significant organic traffic growth. When you guide Googlebot to your most important content, you’re not just cleaning up your site—you’re directly impacting your client’s bottom line.
The Common Culprits: Where Crawl Budget Goes to Waste
Before we can automate a fix, we have to understand the root of the problem. On large sites, crawl budget is typically wasted in a few key areas that multiply at scale.
Parameter Pollution
Faceted navigation (e.g., filtering by size, color, brand) is great for users but can be a nightmare for crawlers. As Screaming Frog’s guide on the topic explains, tracking parameters and messy filters can create thousands of duplicate or near-duplicate URLs. To Google, site.com/shirts?color=blue and site.com/shirts?color=blue&size=m can look like entirely different pages, even though they show the same content. The crawler gets lost in a sea of variations, wasting its budget.
Endless Redirect Chains
When a page moves, you use a redirect. But when Page A redirects to Page B, which later redirects to Page C, you create a redirect chain. According to Ahrefs data, 8.7% of websites have redirect chains, a common issue that forces Googlebot to make multiple “hops” to find the final page. Each hop consumes a little more of that precious crawl budget.
Low-Value Pages and 404 Errors
This category includes everything from expired promotional pages and thin tag pages to the thousands of 404 “Not Found” errors that crawlers keep hitting from old internal links. If Googlebot consistently finds dead ends or pages with no unique value, it learns that crawling your site isn’t an efficient use of its time.
The Manual Trap: Why Traditional Methods Don’t Scale
The old-school approach involved manually exporting server log files, running a site-wide crawl that could take days (and crash a computer), and trying to cross-reference the data in massive spreadsheets.
For an agency, this manual process is a killer. It’s:
-
Time-Intensive: It can take an SEO specialist days to complete for just one client.
-
Error-Prone: The sheer volume of data makes human error almost inevitable.
-
Not Scalable: You can’t repeat this process efficiently every month across multiple large client accounts.
This manual trap prevents agencies from proactively managing site health, leaving them to react to indexing problems only after they’ve already hurt performance.
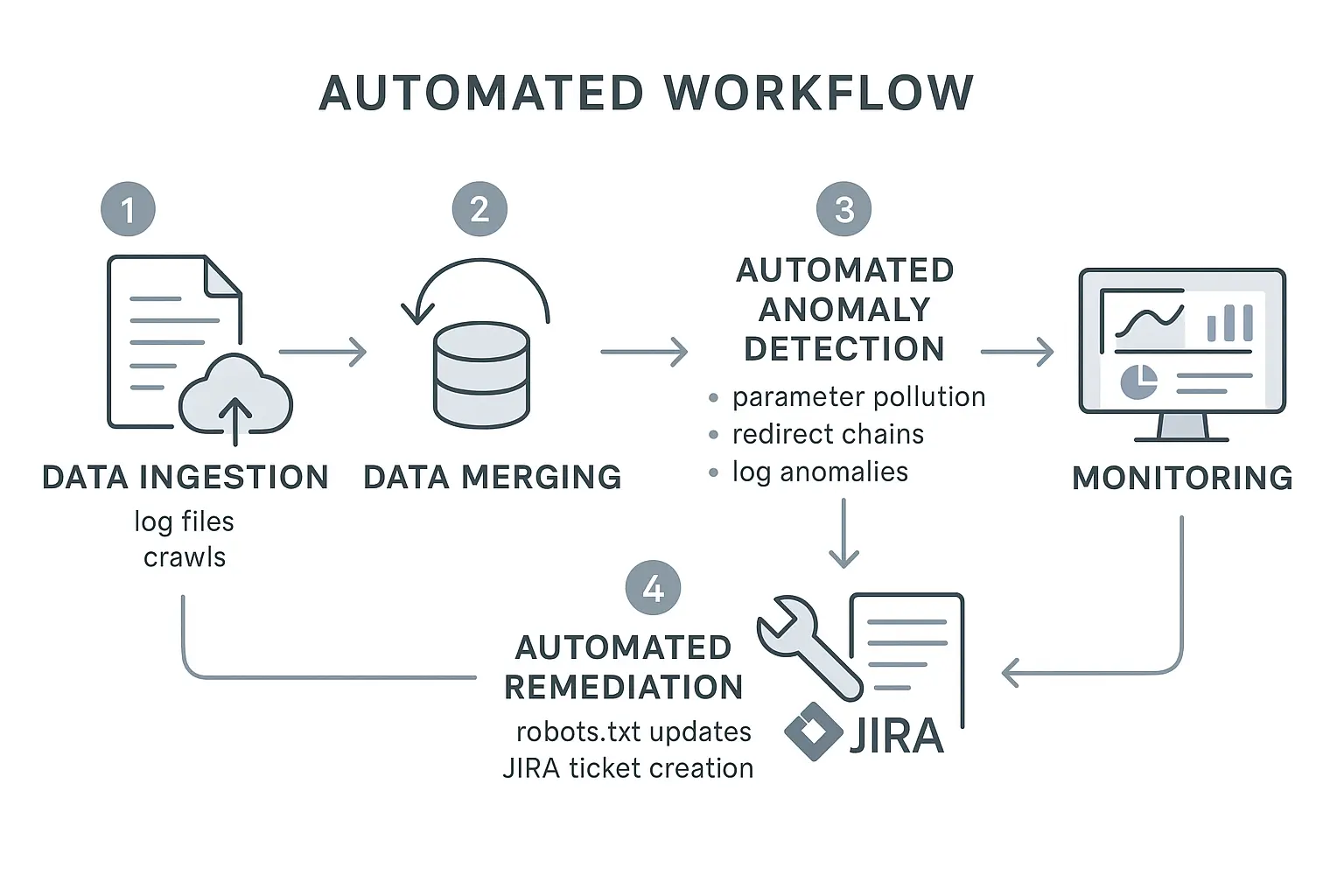
The Automated Workflow: A Scalable Approach for Agencies
Instead of manually hunting for needles in a digital haystack, a modern, automated workflow can systematically identify and prioritize crawl budget issues at scale. This turns a complex technical task into a manageable and repeatable process.
Here’s how to implement this workflow for your clients.
Step 1: Automated Log File Analysis
Your server’s log files are the ultimate source of truth. They record every single request made to your server, including every visit from Googlebot. Tools that automatically parse and analyze these logs show you exactly where Google is spending its time—not just where you think it is. This is often the source of the first “aha moment,” revealing that Googlebot is obsessed with a section of the site you thought was unimportant.
Step 2: Automated Site Crawls to Map the Known Universe
While log files show you what Google sees, a regular, automated site crawl maps out what should be seen. This crawl follows all the internal links on the site to create a complete picture of its architecture. This foundational step of any comprehensive technical SEO audit creates a clean baseline to compare against the log file data.
Step 3: AI-Powered Cross-Referencing and Anomaly Detection
This is where automation becomes a superpower. By comparing the log file data (what Googlebot is crawling) with the site crawl data (what you want it to crawl), you can instantly spot critical anomalies:
-
Crawl Waste: Identify URLs that Googlebot hits frequently but that aren’t part of your site’s intended structure—like those pesky parameter URLs.
-
Orphan Pages: Discover important pages that exist on the site but get little to no crawl attention because of poor internal linking.
-
High-Frequency Errors: Pinpoint which 404 errors and redirect chains are wasting the most crawl budget so you can prioritize fixing them.
Step 4: Generating Prioritized Action Items
The output of this automated analysis shouldn’t be another giant spreadsheet; it should be a clear, prioritized action list for your team. Instead of “look for crawl issues,” your team gets specific tasks like:
-
“Block the ?sessionid= parameter in robots.txt.”
-
“Fix the 3-hop redirect chain originating from the 2019 holiday campaign.”
-
“Consolidate and noindex the 5,000 thin tag pages that are crawled daily but generate no traffic.”
This level of precision is crucial for effectively scaling SEO services and showing clients tangible progress.
Putting It All Together: The Agency Advantage
Implementing an automated crawl budget optimization workflow fundamentally changes how an agency can service large clients. It empowers your team by:
-
Freeing Up Strategists: Automation handles the data-crunching, allowing your SEO experts to focus on high-level strategy and client communication.
-
Demonstrating Proactive Value: You can find and fix major technical issues before they become performance problems, proving your value month after month.
-
Driving Measurable Results: By ensuring a client’s most valuable pages are crawled and indexed efficiently, you create a direct path to improved rankings and organic traffic.
For agencies that want to deliver this level of technical excellence without building an entire in-house department, a white-label SEO partner can provide the tools and expertise to execute this workflow seamlessly behind the scenes.
FAQ: Your Crawl Budget Questions, Answered
How do I know if my client’s site has a crawl budget problem?
Common symptoms include new content taking a long time to get indexed, or changes to existing pages (like title tag updates) not being reflected in Google’s search results for weeks. The Crawl Stats report in Google Search Console is a great place to start looking for anomalies.
Is crawl budget only a problem for e-commerce sites?
Not at all. Any large website can face crawl budget issues. This includes major publishers with millions of articles, SaaS companies with extensive documentation, and large corporate sites with decades of accumulated content.
What’s the difference between crawl budget and indexation?
Think of it as a two-step process. Crawling is Googlebot discovering your page exists. Indexing is Google analyzing that page and adding it to its massive database to be shown in search results. If a valuable page isn’t crawled, it has zero chance of being indexed.
Can I just submit a sitemap and be done with it?
A sitemap is an essential and highly recommended guide for search engines. But it’s a suggestion, not a command. Googlebot will still discover URLs by following links on your site and from external sources, so a clean site architecture is non-negotiable.

From Insight to Impact
For agencies managing enterprise-level accounts, crawl budget optimization isn’t just a technical SEO chore—it’s a strategic imperative. Trying to manage it manually is no longer feasible. By embracing an automated workflow, you can move from reacting to problems to proactively unlocking your clients’ organic growth potential.
Start by taking a look at a client’s Crawl Stats report in Google Search Console. Are you seeing an unexpectedly high number of requests for pages that don’t matter? That’s your first clue that a deeper, more automated analysis could be the key to their next level of growth.